模型部署阶段,如何应对训练和算力挑战
作者 | 陈巍 责编 | 曾浩辰
出品 | NPCon(新程序员大会)
五、LLMOps 是如何解决这些问题的?
六、芯片选择有妙招

大模型之前:Transformer 同时促进语言和图像算法
大模型部署在 AI 领域至关重要,因为其效果决定着能否获得资金支持。仅有模型的高精度并不足够,低成本模型的运维也很关键。从我们的主要 AI 和算法视角来看,早期阶段涵盖了视觉和语言模型,而语言模型最初并不是焦点,产业进展较慢。
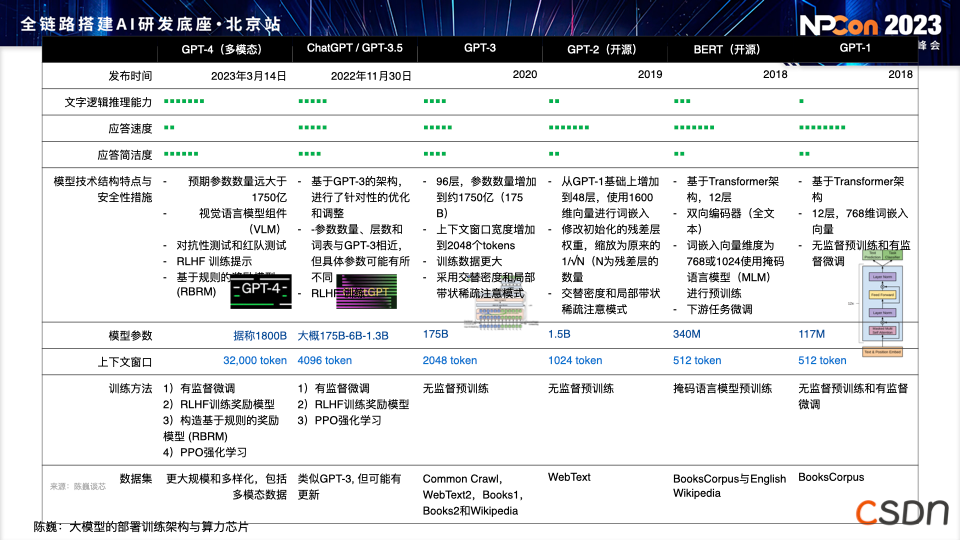
然而,随着近年来 Transformer 技术的突破,人们开始认识到 Transformers 技术不仅可用于语音、语义识别,还可以应用于视觉领域。在 Transformer 架构的基础上,我们将整个语音、语义和图像算法领域进行了统一。当然,Transformer 并不是一个终极架构,更多更高效的算法也在出现。
大模型的本质有不同的解释。从我们多年的经验来看,大模型是人类在客观实践中对客观事物的认知。它是知识的高度压缩和反馈,其中知识压缩是存储过程,而反馈则是计算过程。模型的大小通常反映了存储的知识量和反馈的复杂度能力,这两者总体上反映了模型的整体能力。大模型的出现并没有明显增加计算要求,相反,它提升了部署方面的需求。


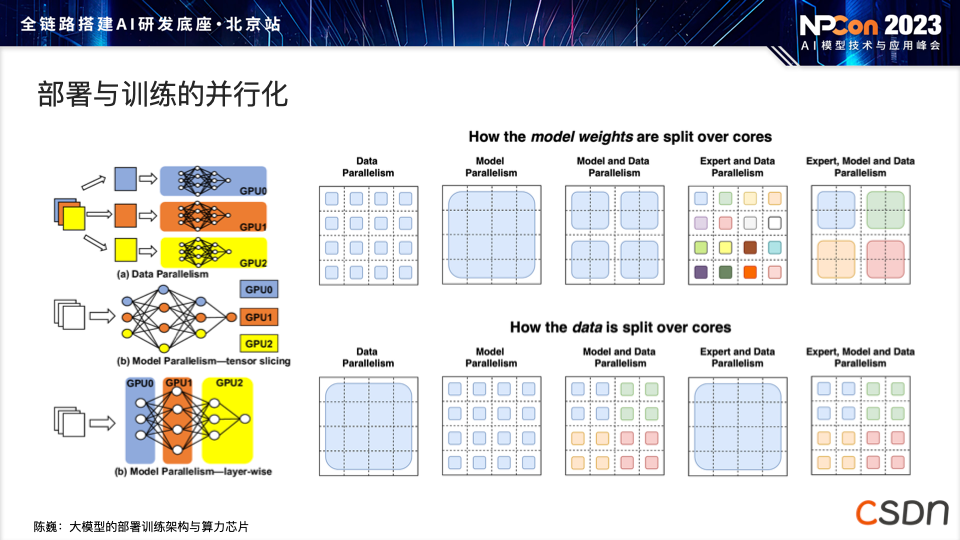
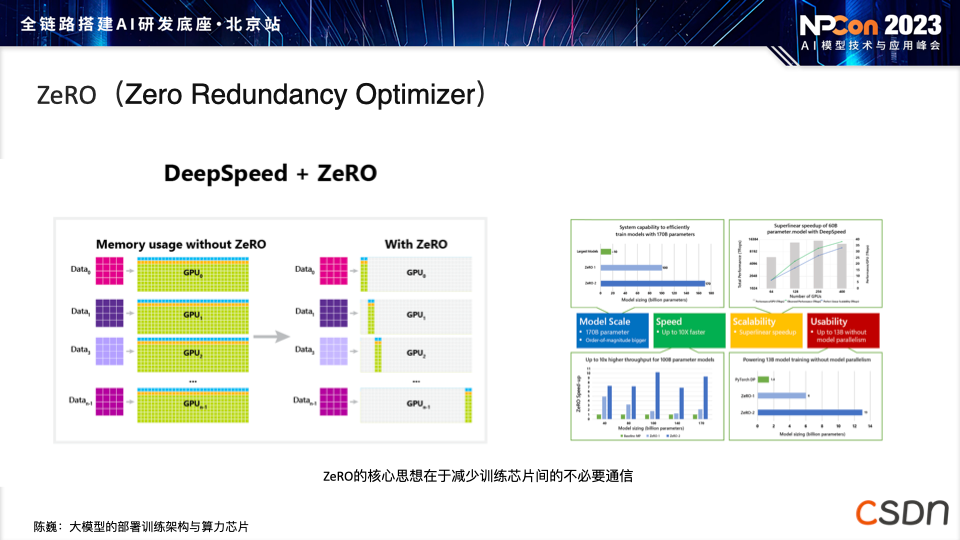
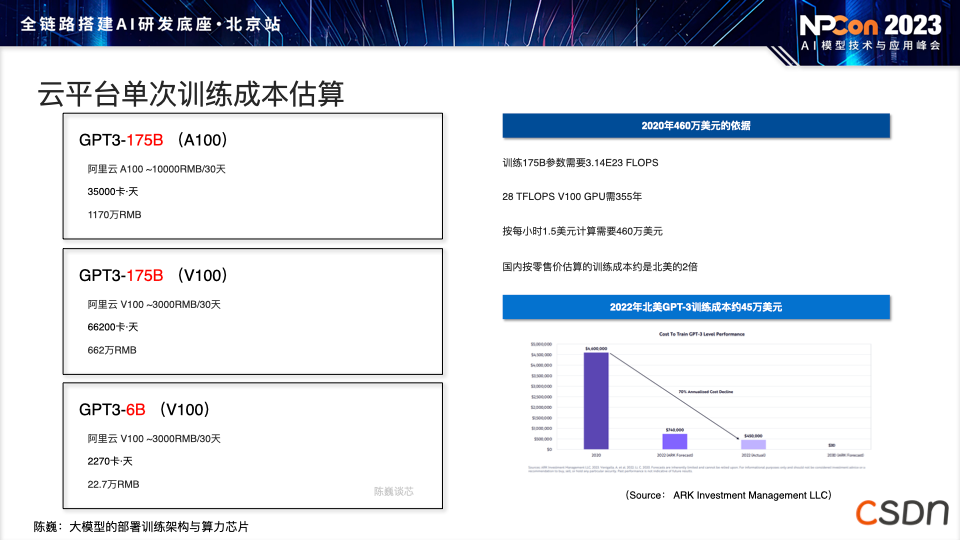
数据量并不是越多越好,过多的数据之间可能导致遗忘效果,以及模型本身在各种冲突信息中学到一些不好的东西。 随着模型的不断增多,许多模型都采用了 Transformer 或类似于 LLaMA 的架构,模型的同质化现象愈发常见。 大模型部署和训练对芯片的算力和存力提出了很高的要求,AI 界由于大模型第一次受到了 CPU 和 GPU 的硬件支撑限制。




不只是模型:部署的额外考量